The OpenTelemetry Architecture
OpenTelemetry is a large project, made of many different types of artifacts: specifications, conventions, working groups and other community resources, and software. The software provided by the OpenTelemetry project consists of the following components:
- The OpenTelemetry Protocol (OTLP) defines the encoding, transportation, and delivery method for telemetry data. It further defines gRPC and HTTP protocols (with more in the works, like Arrow) to ensure that different platforms and tools can exchange data in a standard, standardized format.
- The Application Programming Interfaces (OTel APIs) are “translations” of the OpenTelemetry API specification to language-specific interfaces implemented by the language-specific Software Development Kits.
- The Software Development Kits (OTel SDKs) are implementations of the OpenTelemetry APIs and for specific programming languages. They also include instrumentations, i.e., the logic that collects telemetry based on specific frameworks and libraries your application may be using and has the exporter facilities to transmit the telemetry outside your application.
- The OpenTelemetry Collector is a vendor-agnostic component for receiving, processing, and exporting telemetry data. It replaces the need for vendor-specific agents, and it comprises three main types of components:
- Receivers: Components that handle the ingestion of OTel signals.
- Processors: Components that modify the signals.
- Exporters: Components that send the signals to observability backends and APIs.

An overview of the OpenTelemetry architecture based on the OpenTelemetry Documentation
The architecture diagram above illustrates how OpenTelemetry integrates into a cloud-native environment. Shared infrastructure components, such as cloud vendors or Kubernetes, can generate telemetry and send it to the collector or directly send the data to the backend (as illustrated for Vercel). The same applies to managed components, frameworks, and APIs. The responsibility of storing, analyzing, and visualizing the telemetry is delegated to open-source or commercial observability tools and vendors.
Observability Signals: Metrics, Logs, Traces and more
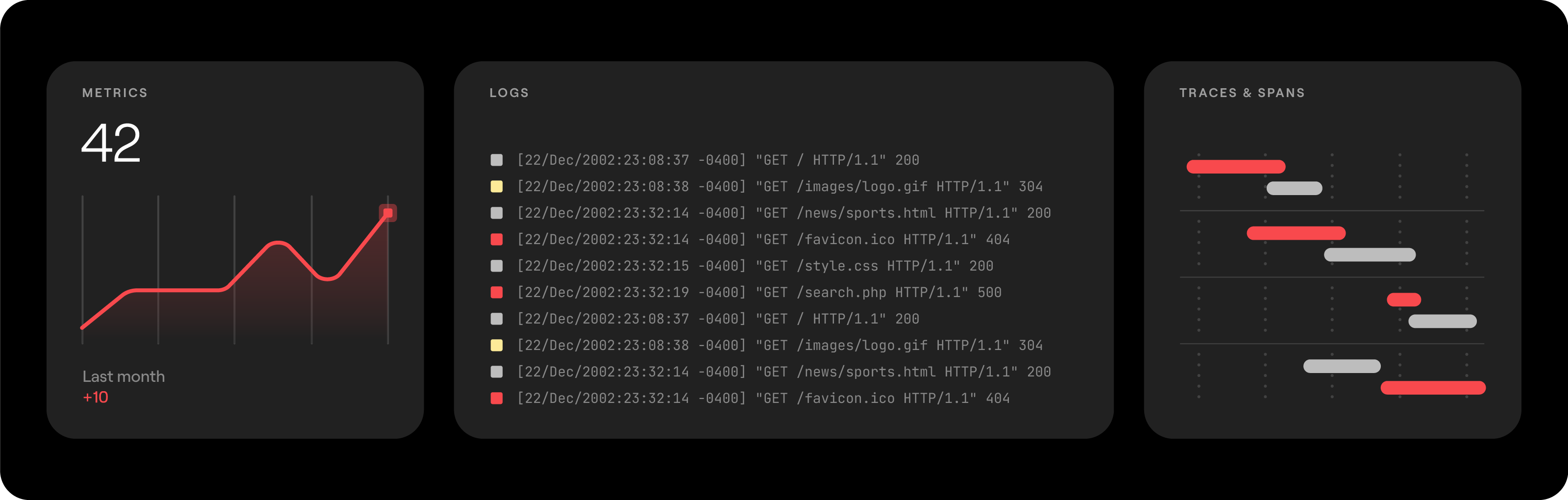
The Obsersvability Signals. Metrics, Logs, Traces.
In the OpenTelemetry terminology, different types of telemetry are known as signals. OpenTelemetry provides support for the classic “three pillars” (metrics, logs, and traces) and is expanding coverage to more:
- Metrics are data collected over time and represent a measurement of a resource, i.e., time series. For example, the CPU utilization of a host, the count of Pods in a Kubernetes cluster, or the request count of a service can all be considered metrics.
- Logs, which can be structured or unstructured, provide information about events occurring in various components. Logs are annotated with their severity to denote the offer of valuable insights at different levels of importance. Developers commonly use logs in production environments for debugging purposes.
- Traces (or distributed tracing) involves capturing the path taken by a request within the various components of a (distributed) application, including timing information, errors encountered, and relevant attributes to analyze the performance and behavior of cloud-native applications.
- Profiles, currently under development in OpenTelemetry, measure the runtime behavior of an application by taking snapshots of executed code at various points in time. This allows for identifying optimization opportunities in terms of CPU and memory consumption, as well as hot spots for execution time.
Correlations of OpenTelemetry signals
Telemetry from different signals is related in OpenTelemetry in three main ways:
- Correlation by timestamp: all telemetry is annotated with Unix-like timestamps with nanosecond precision about when it was collected.
- Correlation by resource: resources are metadata that describe which system generated a certain piece of telemetry. Spans, logs, metrics and profiles generated by the same process with the same SDK setup will have common resource metadata.
- Correlation between signals: these are bespoke correlations between signals, like logs carrying the active trace context at the time of collection, so that you know which span was active when the log was created.
OpenTelemetry resources
In OpenTelemetry, metadata about the telemetry can be specified at multiple levels. For example, a span describing the serving of an HTTP request will have a set of metadata describing which HTTP method was used, the request's path, the status code returned by the response, how large the payloads of requests and responses were in terms of bytes, etc.
Which system generates the telemetry, however, is described via resources. For example, a containerized process running inside a Kubernetes pod will be described by metadata like the process identifier (pid), the path of the executable and the process arguments, the container identifier and name, the pod uid and name, the namespace uid and name, etc.
OpenTelemetry resources are shared across signals. When an OpenTelemetry SDK is initialized in an application, that application’s resource is created by composing the metadata discovered by the configured resource detectors, and the resulting resource metadata is sent alongside all the telemetry produced by the application over its lifetime. The resulting, consistent metadata is extremely valuable when querying different signals in different observability tools, as it allows more robust and straightforward correlation than just by timestamp and ensures better metadata consistency across signals.
Correlations between signals
Some signals can have bespoke correlations between them, which are based on the trace context concept.
In a nutshell, the trace context is two identifiers combined: the identifier of the overall trace being recorded, and that of a span. The trace context is encoded according to standards like W3C Trace Context and passed along from clients to servers over, for example, HTTP or gRPC requests or in message metadata using Kafka. By receiving a request or a message carrying a trace context, the instrumentation in the process receiving them, knows which trace is being continued, and which span is going to be the parent of the span the instrumentation itself will create. As instrumentations inside a process create spans, they keep track of which are currently started and not yet ended. Conceptually, it works like a stack, where the latest span created when serving a specific request is put on the top, and the span currently at the top of the stack is said to be active. For more information about OpenTelemetry instrumentations, refer to the Instrumentation of telemetry data section.
OpenTelemetry uses the trace context to relate between signals in the following ways:
- Logs to Tracing: logs carry the trace and span identifiers of the span being currently active.
- Metrics to Tracing: metric data points can carry exemplars, which are “pointers” using the trace contexts to some of the spans that were active as the metric was modified (e.g., which span was active as the counter was increased).
Profiles to Tracing: the profile can record which spans are active as the profile’s samples are collected.
Instrumentation of telemetry data
In OpenTelemetry, telemetry is produced by instrumentation, which is additional logic provided by the OpenTelemetry SDK (automatic instrumentation) or created by coding directly against the OpenTelemetry API (manual instrumentation).
Automatic instrumentations are often coded via Aspect-oriented programming, creating wrappers around APIs, or using library-provided facilities like middleware to hook into the processing of requests and responses. This usually makes automatic instrumentations specific to the particular programming language, library, and framework to instrument, and even specific versions thereof.
OpenTelemetry SDKs are supported in over 11 programming languages, including Java, JavaScript, Python and Go, and offer hundreds of different automatic instrumentations across the various languages.
The OpenTelemtry Collector
The OpenTelemtry Collector is an optional, but widely-adopted component, responsible for collecting, processing, forwarding, analyzing, and visualizing signaling data.
The Collector’s processing capabilities are essential for managing the collection of telemetry across large systems, as the amount of data produced can be enormous and often requires pre-processing steps like sampling or aggregation.
The Collector includes components that perform tasks such as data compression, sampling, removal, or modification before sending it to one or more backends for storing, alerting and querying.
Collectors are often deployed by end users “near their applications”, e.g. as deployments of daemonsets in the Kubernetes clusters hosting the applications that sent those collectors telemetry, but they are also commonplace in the ingestion pipelines of observability vendors that support OpenTelemtry.
OpenTelemetry semantic conventions
The OpenTelemetry semantic conventions are a growing set of standardized attributes to encode metadata about telemetry. Some semantic conventions apply to multiple signals, others not, depending on the kind of metadata they encode. This ensures that the attributes attached to telemetry, such as the hostname of the host that produced the signal of the HTTP method used by requests, are applied consistently to the produced telemetry and can, therefore, be consistently used to aggregate and query telemetry.
The impact of OpenTelemetry
OpenTelemetry has revolutionized how telemetry data is created and transported in a vendor-neutral fashion. For the first time in the history of IT, platform and cloud providers, application providers, and framework developers can generate and transmit data critical for the observability of their system without being tied to a specific vendor, fostering a more open and flexible approach to observability. This paradigm shift empowers organizations to collect and analyze telemetry effectively, enhancing their understanding of system behavior and improving overall observability.
The adoption of OpenTelemetry is increasing rapidly:
- Over 70 observability vendors are now supporting OpenTelemetry.
- Hundreds of integrations are available, from platforms like AWS, Vercel, or Kubernetes, frameworks like Next.js or Springframework, and software components like ElasticSearch, NGINX, or Kafka, to services like Kong or Cloudflare.
- Adopters include well-known companies like eBay, GitHub, Skyscanner, and Shopify.
Where did OpenTelemetry come from? OpenTracing and OpenCensus.
OpenTelemetry originated from the joining of two observability communities and their projects: OpenTracing and OpenCensus.
OpenTracing, co-founded by Ben Sigelman, one of the authors of the Google Dapper paper and co-founder of the observability vendor LightStep, initially developed a set of vendor-neutral APIs and instrumentations for distributed tracing. It focused on tracing and collaborated with industry experts from open-source projects like Skywalking, Jaeger and Zipkin.
OpenCensus is an open-source project that originated from Google. It consists of a set of libraries, collectively called Census, which are used to capture traces and metrics from services automatically. Other cloud and monitoring tool vendors later joined the project, contributing to its development and adoption.
The OpenTracing and OpenCensus projects have been discontinued and have served as the foundation for OpenTelemetry, intending to consolidate into one de-facto industry standard around Observability rather than having distinct, competing ones.
Is OpenTelemetry a standard?
While there is no standards organization backing it, OpenTelemetry is arguably already the de-facto standard for collecting and processing telemetry across the industry, and especially in the cloud-native space. There is also significant activity in making OpenTelemetry interoperate with other de-facto standards in the cloud-native space, like Prometheus and OpenMetrics, in terms of collecting and processing time series data.
OpenTelemetry is a vendor-agnostic project that enjoys large amounts of contributions from adopters and most commercial observability vendors.
OpenTelemetry can be seamlessly integrated with all major cloud vendors and other platforms, such as Amazon Web Services, Google Cloud Platform, Vercel, or Cloudflare, making it a versatile choice for organizations.
The widespread and growing support of OpenTelemetry across the observability industry and the cloud-native software ecosystem is one of its key advantages. This extensive ecosystem makes it easier for organizations to ingest and export telemetry, regardless of the tools and technologies they employ in their software stacks. The availability of a diverse range of OpenTelemetry-compatible tools and services simplifies the process of collecting, processing, and analyzing telemetry, enabling organizations to gain valuable insights into the performance and behavior of their systems.
As an open-source standard, the vendor-agnostic APIs and SDKs of OpenTelemetry allow teams to instrument their applications to generate logs, distributed traces and metrics in a way that is consistent across programming languages and vendor-independent in terms of telemetry collection and processing.
Many vendors of existing APM solutions are contributing to OpenTelemetry, aiming at making OpenTelemetry a drop in replacement for legacy proprietary data collectors in the future.
Benefits of OpenTelemetry
OpenTelemetry offers many advantages, including:
- Standardization: Metrics, logs, traces, and their associated resources and metadata are standardized in a vendor-neutral manner, allowing you to use a variety of open-source and commercial tools for processing, storing, and visualizing telemetry without being tied to a specific solution.
- Consistent Instrumentation: The OpenTelemetry APIs and SDKs enable consistent and standardized instrumentation of your code, which can seamlessly integrate with data generated by libraries and third-party systems.
- Enhanced Observability: OpenTelemetry provides a unified framework for collecting, processing, and exporting telemetry, enabling enhanced observability and deeper insights into the behavior and performance of your systems.
- Portability: OpenTelemetry's platform- and language-agnostic approach allows you to easily collect and analyze telemetry data across different environments, platforms, and programming languages.
- Extensibility: OpenTelemetry is designed to be extensible, allowing you to integrate with existing monitoring solutions and technologies, such as Prometheus, Jaeger, and Grafana, or to develop custom integrations.
- Community Support: OpenTelemetry is an open-source project backed by a vibrant community of contributors, including all the major and most minor observability vendors and a variety of adopting companies of all sizes, ensuring ongoing development, innovation, and support.
What are the challenges of OpenTelemetry?
OpenTelemetry is a set of technologies that can have a steep learning curve for adopters without significant observability expertise. It can be a challenge to collect consistently the necessary attributes and resource information to provide context and generate value. OpenTelemetry data collection tools, libraries, and frameworks must be configured appropriately to harness semantic conventions effectively, like configuring a Kubernetes resource detector ensures the automatic application of relevant Kubernetes attributes to all signals.
Developers manually instrumenting their code must add metadata in the format specified by semantic conventions. To simplify this process and ensure consistent instrumentation, an OpenTelemetry-native solution should offer hints and automation. This facilitates the creation of traces, metrics, and logs that can be correlated to identify dependencies and issues swiftly.